1248
2024-09-15
导读
GPT大语言模型(以下简称“大模型/大语言模型”)以其庞大的参数规模、复杂的网络结构和出色的泛化能力,展现出了跨领域知识理解、思维链推理等通用人工智能能力,为各行业的业务智能化提供了新思路和新动能。然而,由于参数量大、微调技术难度高、典型实践经验少等特点,如何设计垂直领域大模型建设思路、开展行业语料加工、构建提示词工程等关键技术内容,是企业开展大模型建设和应用面临的难点。
佰聆数据基于多年来在自然语言处理、深度学习技术领域的深厚积累以及丰富的电力行业算法模型与应用经验,积极投入大模型的技术创新研究和应用探索,沉淀形成了体系化大模型建设和应用能力,在数据生成、知识问答、文本比对、智能写作四个细分技术领域构建了核心能力引擎,并以此面向具体业务场景形成了系列场景化产品。我们将通过系列文章分享公司关于行业垂直领域大模型建设及应用的思考以及典型实践成果,为企业开展大模型建设和应用提供一些参考,共同推动更多行业大模型建设和应用。
一、大预言模型应用思考
大语言模型擅长的业务
当前,大语言模型所展现的通用人工智能能力可以为其广泛的应用赋能,主要体现在以下方面:
⭕ 通用自然语言理解能力
⭕ 基础文案生成、代码编写、数学计算能力
⭕ 基础多模态信息处理能力
⭕ 借助工具与外界交互能力
⭕ 跨领域整合和应用知识的能力
⭕ 小样本学习能力
结合大模型技术、能力特征,以电力行业为示例,我们总结了大模型擅长完成的业务主要包括以下四大类:
(1)文档内容校验类:不同文本间的细则内容的笛卡尔积式比对,海量、实时,输出潜在的矛盾点或一致性结论;包括供应商文件审查、试验报告校验、工单分类、知识纠错等。
(2)知识问答类:基于现有的相对稳定、不具备强时效性的知识文档,可实现“静态型”知识管理和应用类业务;典型场景包括:知识检索、知识问答、指标含义问答、文档解读等。
(3)数据结果生成类:基于现有实体数据(数据库),依托数据库查询、文件检索等插件可实现基于实体数据的“动态型”数据结果生成和分析;典型场景包括:数据查询、数据处理 、统计图表分析等。
(4)文案生成类:文字编写工作量较大,主要以提供文字初稿的方式辅助写作,内容的深度要求相对较低;典型场景包括:工作汇报、论文、专利、宣传文案、会议通知、会议纪要等。
大语言模型应用于电力业务的局限性
大模型应用落地垂直领域解决具体业务问题,并非一蹴而就,需要综合考量大模型能力与业务实质、需求的深度融合贯通问题。以电力行业为例,大模型的局限性表现如下:
1
能力偏向性
大模型擅长非结构化“语言型”知识应用,不擅长结构化数据的分析预测;另外,大模型结果可解读性、过程可干预性存在天然局限;而电网企业较多业务涉及多源异构数据,流程环节多、业务需求特征差异大,并且对业务结果可解读性要求高。
2
AI通用风险
大模型存在生成虚假信息、版权争议、事实性错误、知识盲区、常识偏差等概率论的不确定性;而电网企业大多数业务对结果的准确性要求较高以及业务规程、制度等相对严格,对模型决策可行性、可靠性要求高。
3
业务偏见性
基于大模型的业务模式与电网企业已固化业务可能存在差异,对数据解读、应用方式也与传统的业务模式存在差异;而电网企业已存在大量专用“小”模型的业务应用实践,部分已深入融合业务并取得良好效果,并且当前模型构建、管理和应用相对繁琐,有提升需求。
由此可见,单纯依靠大语言模型进行业务应用,难以满足如电网企业综合多能力的业务融合和连贯决策、输出结果及决策依据的高确定性、业务经验和算法模型持续运营等的需求。
大语言模型应用模式探讨
我们通过十余项大模型应用场景研究和实践,总结沉淀了大模型+专用小模型的融合应用模式——充分利用大语言模型的跨领域整合和应用知识、人机交互能力等特征,以大语言模型为底座,将大模型基础能力、各类专用模型已具备能力统一融合,并建设统一对外服务接口,以自然语言交互方式供业务应用、业务人员交互式调用,从而实现大模型、专用模型所沉淀的业务知识、算法能力的深度整合,在一定程度上解决前述的大语言模型能力偏向性、业务偏见性等不足。

图1 大模型+专用模型的融合应用架构
其中,大模型与专用模型融合应用的方式主要有如下3种:
调用:模型编排,取长补短,各司其职
将原有专用模型接口化改造成API或可调用函数,大模型按需调用、运行专用模型或读取专用模型的结果,将专用模型的结果作为大模型的输入。
优化:利用大模型提升专用模型效果
大模型作为特征提取器,提取深层特征以替换或注入原有特征,作为增强的特征输入专用模型,为专用模型提供更强的数据源,在不改变原算法的基础上重训练/优化专用模型。
重构:构建专用模型同类能力
大模型通过提示工程、微调、新增网络层等方式实现相同能力,相当于改变了原有专用模型的算法,重新设计和构建新的模型。
大模型与专用模型的融合应用模式,一是综合利用大模型、专用模型能力特征,敏捷应用于各类典型业务场景,提升了业务覆盖能力;二是依托大模型、专用模型的统一运营,实现模型持续优化改造等,促进知识、能力持续提升;三是通过友好的人机交互方式,支撑业务人员更自由、便捷地综合利用模型能力开展业务决策,提升自主、动态决策能力。
二、大模型研究及应用框架
公司持续总结大模型探索、实践经验,采用基座大模型+模型微调+能力引擎搭建+场景化产品建设的思路,已自主研发了“基于思维链推理的文本智能比对”、“基于NL2SQL的数据问答”、“AI 写作助手”、“基于检索增强的智能问答”四个核心能力引擎,并以此开展十余项定制化场景产品的建设,为业务赋能,提升业务质效。
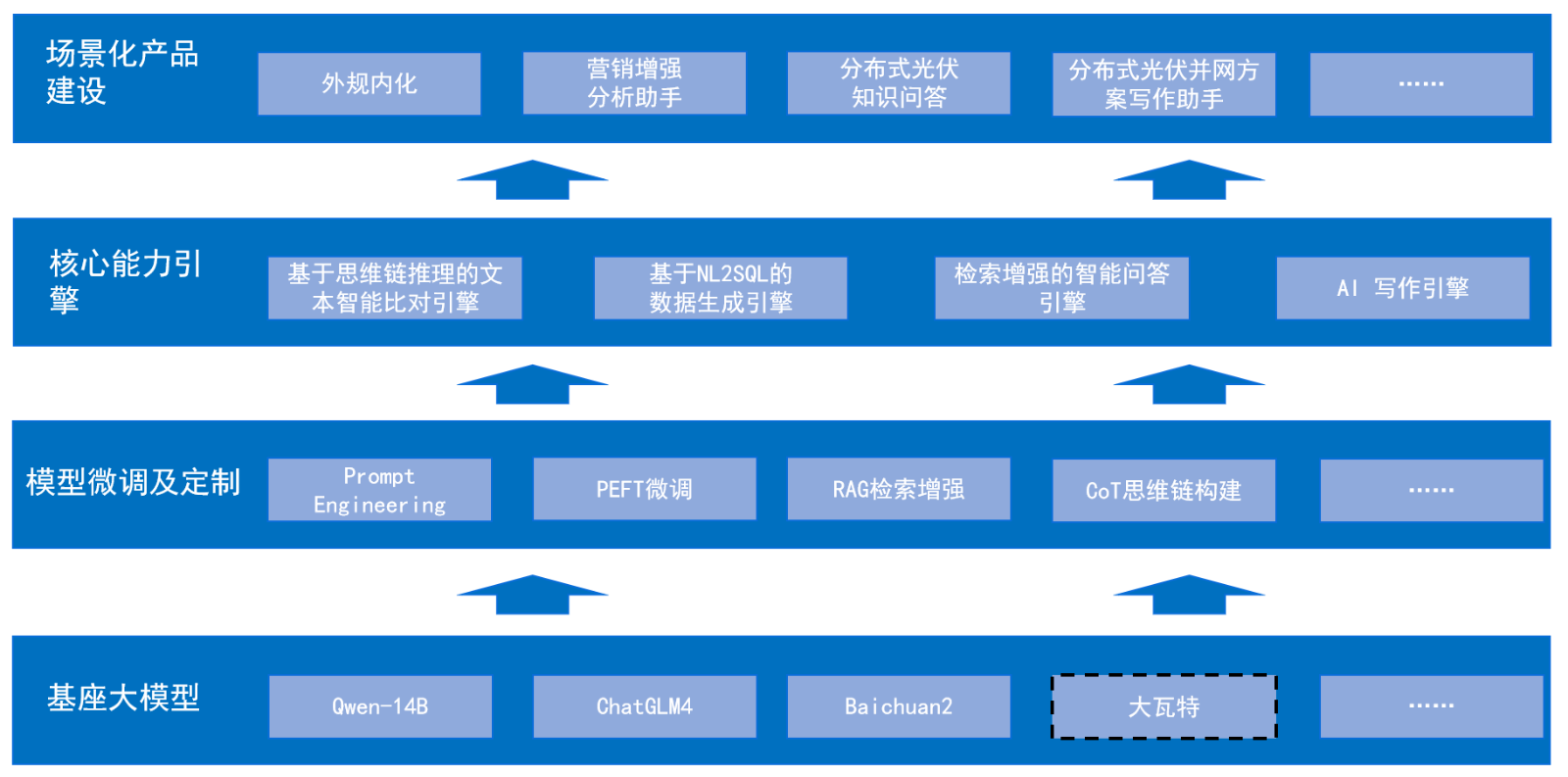
图2 公司大模型研究及应用框架
01
基于思维链推理的文本智能比对引擎
企业文本比对类工作中,传统NLP技术难以满足要求。一是无法利用先验知识,依赖浅层语义特征,标注语料需求量大;二是语义匹配难以准确处理文本条目间抽象、模糊的语义关系;三是训练工作量大,泛化能力难以保障。
能力简介:
利用大模型的小样本学习能力,结合少量人工标注语料批量生成包含关键信息的高质量训练样本;基于大模型的思维链(CoT)推理能力,针对训练样本构造逻辑判断思维链;综合利用提示词工程、Prefix Tuning等技术手段,固化业务判断逻辑,提升大模型对目标场景的业务理解和逻辑推理能力,满足文本内容智能识别、比对等需求。
适用场景:
符合性识别(供应商文件审查、试验报告校验)、归类性识别(工单分类、知识归类)、相关性识别(合规审查、项目查新);
02
基于NL2SQL的数据生成引擎
增强型数据分析是目前数据分析技术的主要趋势。传统数据统计分析模式,主要依靠定制化报表与运维厂商后台取数支撑,数据准备速度无法保障,在处理多个数据源的情况下效率较低;此外,数据分析可交互性差,难以多维度动态开展。
能力简介:
构建基于检索增强(RAG)、思维链推理及小样本学习的技术架构,通过提示词的动态拼接、检索增强、参数高效微调、数据特征适配图表等技术,实现针对性增强目标业务场景的SQL生成能力。
适用场景:
数据查询、数统计图表、数据分析报告、数据治理、标签管理、指标管理等。
03
基于检索增强RAG的知识问答引擎
传统基于NLP、知识图谱等技术构建的知识问答服务,本质上均属于知识匹配检索后的“原始”答案,严重依赖问答题库的人工设计、梳理质量以及知识检索匹配能力,且无法保障准确性。
能力简介:
构建自动化流程对其进行切片及结构化处理,基于预训练语言模型对知识片段进行向量化处理;综合应用检索增强、检索融合(Retrieval Fusion)等技术,准确识别与用户问题相关的知识片段;通过提示词工程激活大模型的知识整合、推理能力。
适用场景:
知识检索、知识问答、指标含义问答、文档解读等。
04
AI写作引擎
专业文档要求撰写者具备深厚的专业知识、严谨的思维逻辑、精准的语言表达能力以及良好的内容组织能力,既要将复杂的信息进行提炼、整理,使之条理清晰、易于理解,还要确保内容的准确性、规范性和有效性。
能力简介:
以外挂知识库的形式存储面向不同专业领域的文本模版及业务语料,通过检索增强技术辅助大模型输出针对特定场景的文本内容,以文本编辑器(如Word、WPS等)插件的形式输出提纲生成、扩写、续写等能力。
适用场景:
总结报告(如工作总结、专题汇报等)、项目材料(可研报告、招投标文件等)、专业写作(如论文、科普文章等)、专题报告(宣传报道、ESG报告等)、日常事务(如通知发文、会议纪要等)等。
三、典型产品/应用场景
公司综合利用研发的大模型核心能力引擎,面向企业内规外法比对、量费数据问答等具体业务场景,形成系列准确性高、适用性强的大模型产品/应用场景。
产品/场景一:
企业内规外法智能比对
企业为适应法律法规不断完善的形势,需及时做好内部规章制度(内规)与外部法律法规(外法)的识别比对,准确判断内规-外法的一致性、识别潜在的矛盾点,并以此完善企业规章制度,保障内规与外法的协同性。
该产品通过构建基于思维链推理的内规外法智能比对能力,模型准确性较传统方法显著提升。
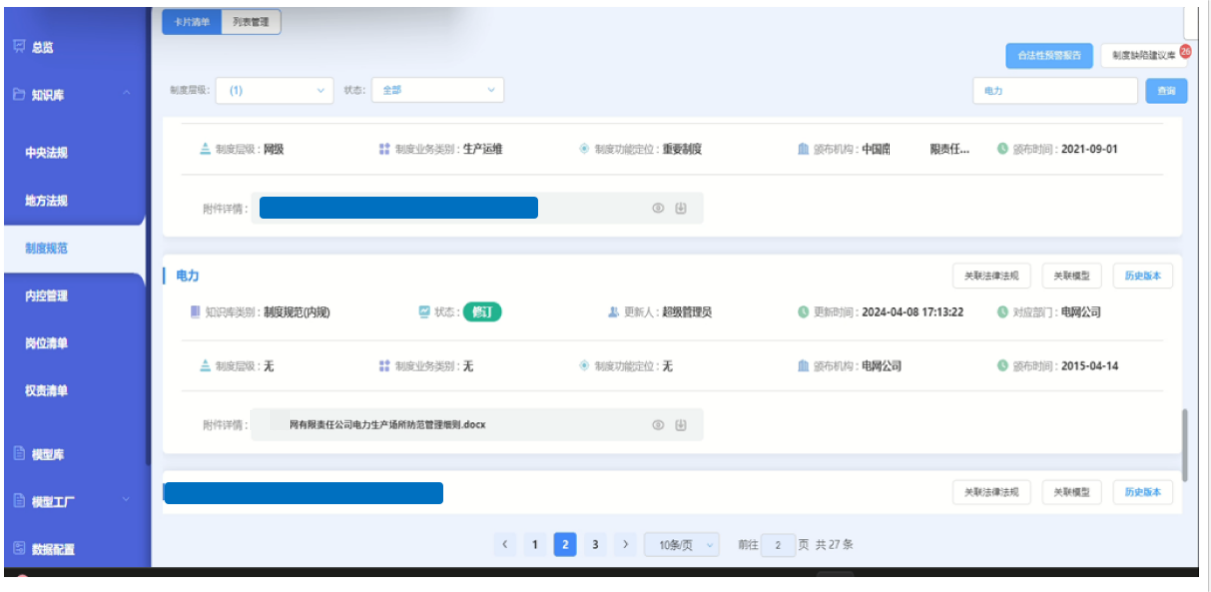
图3 企业内规外法比对产品效果图
产品/场景二:
电力营销量费数据智能生成
电力营销量费相关数据分析场景不断增加、数据集合越来越大、分析要求不断精细化,基层数据自主分析需求日益增加,而传统的数据分析工具或业务人员提需求、IT人员取数的模式难以满足业务需求。
该产品通过提示词工程和检索增强技术,训练大模型理解电力营销量费业务数据表中的表名和字段名,并学习历史同类SQL语句语法等,从而实现以自然语义对话方式的数据查询SQL生成。
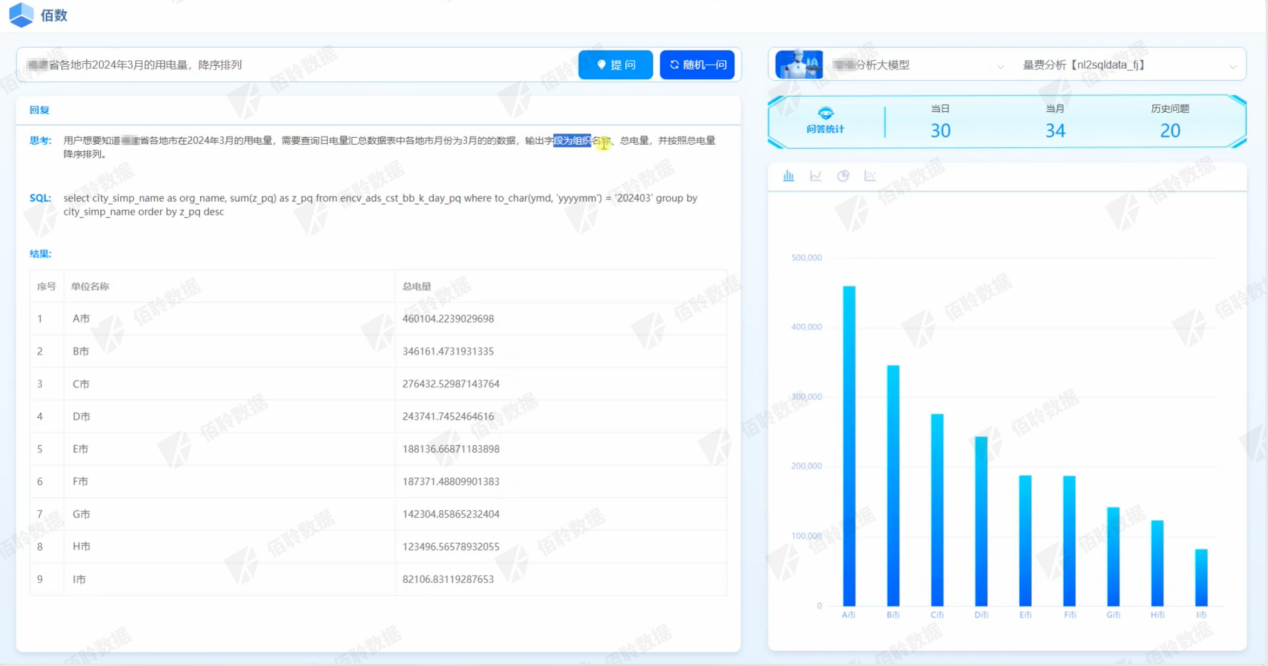
图4 电力营销量费数据智能生成产品效果图
产品/场景三:
安规知识智能问答
电力安全知识跨越设备、调度、安监、营销等各个专业,涉及设备检修、运行巡视、表计更换等各类现场作业工作;业务人员获取和掌握全面、准确的安规知识是安全生产作业的基础。
该产品利用公司基于检索增强RAG的知识问答引擎,对海量安规知识开展增强学习,并通过对安规标准、安规题库等不同行文结构的知识文档设计定制化的知识分块、存储规范,最终实现了高准确性的安规知识问答。
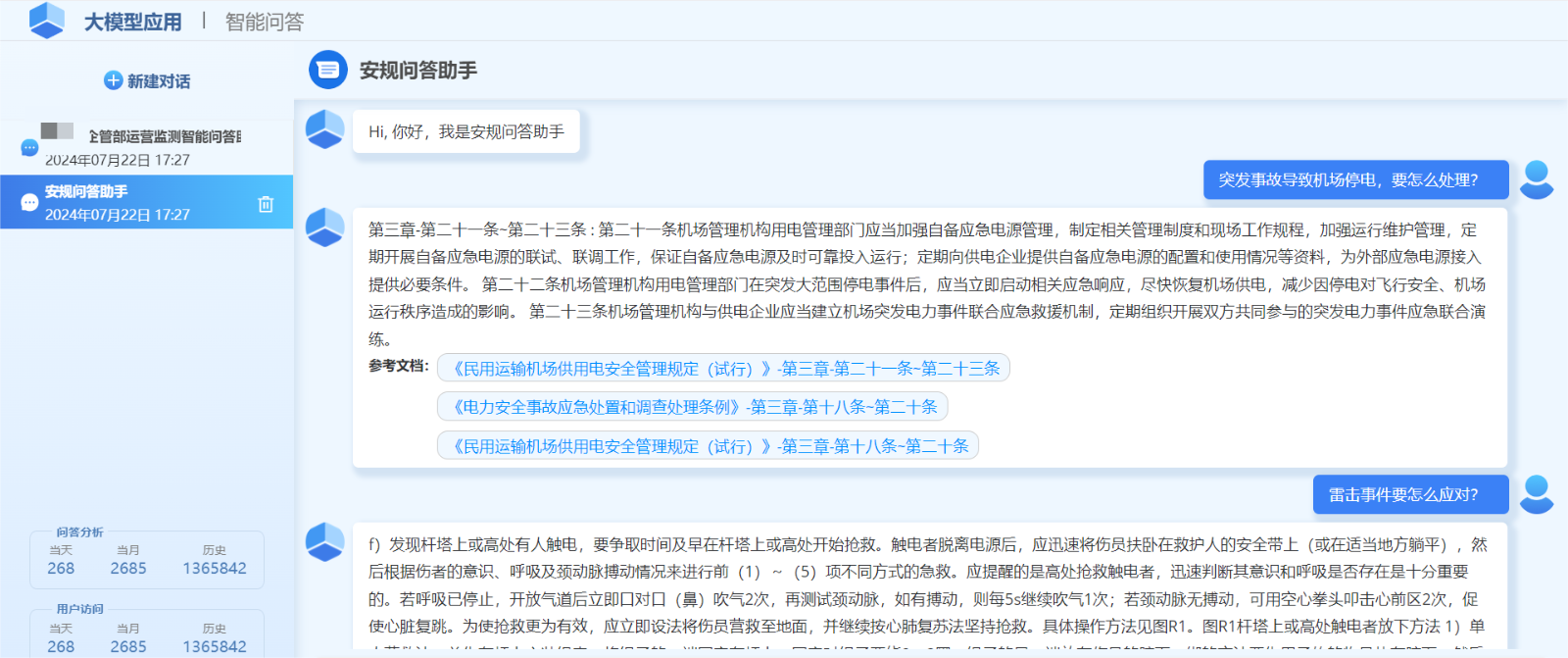
图5 安规知识问答产品效果图
产品/场景四:
分布式光伏业务写作助手
随着分布式光伏规模快速扩大,分布式光伏业务相关文案工作量持续增加;以分布式光伏并网管理为例,涉及并网知识科普宣传、并网申报材料、并网方案、并网工作总结等系列文档编写工作,给业务人员带来了较大的重复性工作量。
该产品面向分布式光伏业务,在AI写作引擎的基础上,通过训练大模型学习分布式光伏并网申报材料、并网方案相关知识,进而形成专业文案的文字生成能力,最终实现以问答、写作插件等方式全面支撑分布式光伏业务相关写作需求。

图6 分布式光伏业务写作助手产品效果图
小结
由于篇幅有限,本文仅对公司关于行业垂直领域大模型建设、应用的思考以及典型实践成果进行简要概述,后续我们将陆续发表系列文章,对公司大模型核心引擎、典型场景的相关内容进行更详细的介绍;下一篇暂定为《基于思维链推理的文本智能比对典型实践》,敬请期待。
 核心产品
核心产品 技术服务
技术服务 电力
电力 金融
金融 制造
制造 政府
政府 通用
通用



 粤公网安备44011602000517号
粤公网安备44011602000517号